Tackling the game Kalah using reinforcement learning - Part 1
23 Oct 2020
Update (2020-11-03): The code is now available on GitHub: https://github.com/torlenor/kalah
- Introduction
- Kalah
- Classic agents
- Reinforcement learning agents
- Training of the RL agents
- Comparison
- Summary
- Outlook
- References
In this article series we are going to talk about reinforcement learning (RL) [1], an exciting and one of the three major parts of machine learning, besides supervised (see Predicting the outcome of a League of Legends match for an example) and unsupervised learning. The idea behind RL is to train a model, usually called an agent, to take actions in an environment so that the cumulative reward over time, which must not necessarily mean real time, is maximized. In contrast to supervised learning, in RL the agent is not fed with labels and is not told what is the “correct” move, but the idea is, that the agent learns by itself in the given environment solely by providing an observation/state of the environment and the gained/lost reward after a taken action.
Here we will use this approach to tackle the game Kalah [2]. To mix things up a little, this time we are going to use PyTorch [3] as our library of choice.
We will show that it is possible to train an RL agent to play better than hard-coded approaches. In the last section we will give an outlook on improvements to the algorithms and what other approaches we could use.
Introduction
Reinforcement learning (RL) is one of the exiting fields of machine learning (ML) which gained popularity over the last years do to advances in computer performance, algorithms and because of the involvement of big technology companies. The research on learning ATARI games by Google’s DeepMind Technologies [4,5] and their subsequent proof that RL can beat humans in go [6], chess and shogi showed that RL can be a powerful tool which will find its way out of toy models into real world applications sooner or later. Even learning complex computer games, like Dota 2 [7] or Starcraft II [8], are no longer just visions, but under certain controlled conditions this is already possible.
Here we will first introduce the game Kalah, followed by implementations of some classic agents for the game, which will serve as our baseline and as a sparing partner for our machine learning models. Afterwards, we will present two simple RL agents for Kalah, show how to train them and compare them to the classic agents. We will show, that it is possible to have simple reinforcement learning models to learn the game Kalah and outperform classic agents, though currently restricted to smaller game boards.
Kalah
Kalah [2] is a two-player game in the Mancala family invented by William Julius Champion, Jr. in 1940.
The game is played on a board and with a number of “seeds”. The board has a certain number of small pits, called houses, on each side (usually 6, but we will also use 4) and a big pit, called the end zone, at each end. The objective of the game is to capture more seeds than your opponent.

Figure 1: A Kalah board $(6,6)$ in the start configuration.
There are various rule sets available and we will take the rule set which is considered standard. It is summarized in the following:
1) You start with 4 or 6 (or whatever you agree on) number of seeds in every of the players pits.
2) The players take turns “sowing” their seeds. The current player takes all the seeds from one of its pits and places them, one by one counter-clockwise into each of the following pits, including its own end zone pit, but not in the opponents end zone pit.
3) If the last sown seed lands in an empty house owned by the current player, and if the opposite house contains seeds, all the seeds in the pit where he placed the last seed and the seeds in the opposite pit belongs to the player and shall be placed into its end zone.
4) If the last sown seed lands in the player’s end zone, the player can take an additional move.
5) When a player does not have any more seeds in its pits, the game ends and the opposing player can take all its remaining seeds and place it in its end zone.
6) The player with the most seeds in its end zone wins.
For many variants of the game it was shown that the first player has a strong advantage when both are playing a perfect game. However, for the $(N_\text{pits}, N_\text{seeds}) = (6,6)$ variant, this is not yet that clear how big the advantage is. There are also additional rules which can mitigate that advantage, but we will not go into detail and if you are interested in that, feel free to consult Wikipedia.
In this article we are going to play with the $(4,4)$, $(6,4)$ and $(6,6)$ variants.
Classic agents
Before we talk about reinforcement learning approaches to playing Kalah, we first present classic agents which will serve as our baseline in the comparisons and which will be used for training. For most of its variations Kalah is a solved game were the first player would win if we would use pre-computed move databases with perfect moves, but we are not going to use them here.
Random agent
This agent, as the name suggests, will randomly choose a move out of all valid moves. This is the simplest approach we can take and it can be implemented essentially with just one line of Python code.
MaxScore agent
The idea behind this agent is, that it will always take the move which gives him the highest score. This can either be a move which will let him sow a seed into its own end zone, or, ideally, it will be a move were it can steel the opponents seeds by hitting an empty pit on its own side of the board.
MaxScoreRepeat agent
The base strategy for this agent is the same as the MaxScore agent. The difference is, that it will prefer a move were it will hit its own end zone with its last seed, meaning that it can take another move. This is implemented in such a way to exploit the possibility of having more than one additional move if the board permits that. This can easily be implemented by always taking a look at the possible moves starting from the left of the board going right and picking the first where a repeating play is possible.
Minimax agent
The minimax algorithm [9] is a very common decision rule in game theory, statistics and many other fields. One tries to minimize the possible loss for a worst case (maximum loss) scenario.
The pseudo code for the algorithm (take from Wikipedia) is given by:
function minimax(node, depth, maximizingPlayer) is
if depth = 0 or node is a terminal node then
return the heuristic value of node
if maximizingPlayer then
value := −∞
for each child of node do
value := max(value, minimax(child, depth − 1, FALSE))
return value
else (* minimizing player *)
value := +∞
for each child of node do
value := min(value, minimax(child, depth − 1, TRUE))
return value
If not otherwise specified, we will use a minimax depth of $D_{max}=4$. In addition we implement alpha-beta pruning [10] to speed up the calculations.
Reinforcement learning agents
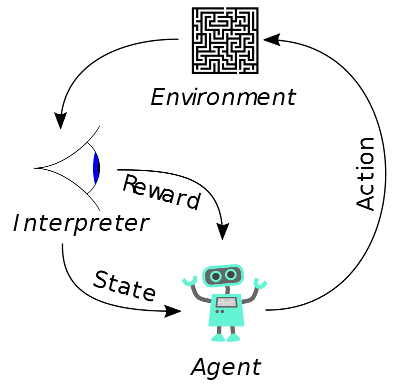
Figure 2: Reinforcement learning. Courtesy of Wikipedia.
Reinforcement learning (RL) is a branch of machine learning dealing with the maximization of cumulative rewards in a given environment. When talking about RL models running in such an environment one is usually talking about agents, a notion we already introduced in the sections above. Reinforcement learning does not need labelled inputs/outputs and the environment is typically sketched as a Markov decision process (MDP).
Usually the way RL works is shown in Figure 2: An agent takes action in a given environment, the action leads to a reward (positive or negative) and a representation of the state of the environment (in our case the Kalah board). The reward and the state are fed back into the agent model.
REINFORCE algorithm
There are many different approaches to reinforcement learning. In our case, we will take, in my opinion, the most straightforward and easy to gasp approach: Policy gradients.
In the policy gradient method, we are directly trying to find the best policy (something which tells us what action to choose in each step of the problem). The algorithm we are going to apply is named REINFORCE and was described in [11] and a good explanation and implementation can be found in [12]. Additionally, a good overview of different algorithms, including REINFORCE, is presented at: https://lilianweng.github.io/lil-log/2018/04/08/policy-gradient-algorithms.html#reinforce
Here we are going to briefly outline the idea behind the algorithm:
1) Initialize the network with random weights.
2) Play an episode and save its $(s, a, r, s’)$ transition.
3) For every step $t=1,2,…,T$: Calculate the discounted reward/return
\[Q_t=\sum^\infty_{k=0}\gamma^kR_{t+k+1}\]where $\gamma$ is the discount factor. $\gamma = 1$ means no discount, all time steps count the same, and $\gamma < 1$ means higher discounts.
4) Calculate the loss function
\[L=-\sum_tQ_t\ln(\pi(s_t,a_t))\]5) Calculate the gradients, use stochastic gradient decent and update the weights of the model, minimizing the loss (therefore, we need the minus sign in step 4 in front of the sum).
6) Repeat from step 2 until problem is considered solved.
$s$ is a state, $s’$ is the new state after taking action $a$ and $r$ is the reward obtained at a specific time step.
An example implementation in PyTorch can be found here, solving the CartPole problem.
Actor-critic algorithm
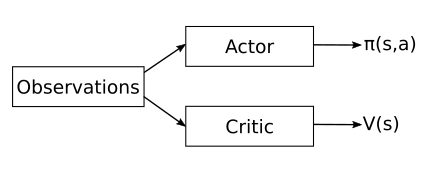
Figure 3: Sketch of the actor-critic model structure.
In case of the actor-critic algorithm [13] a value functions in learned in addition of the policy. This helps reducing the gradient variance. Actor-critic methods consist of two models, which may optionally share parameters:
- The Critic updates the value function $V_\omega$ parameters $\omega$.
- The Actor updates the policy parameters $\theta$ for $\pi_\theta(s,a)$ in the direction suggested by the critic.
An example implementation in PyTorch can be found here.
Training of the RL agents
Training the RL agents turned out to be a challenge. After tuning $\gamma$, learning rate and rewards we were finally able to get an improving REINFORCE agent with win rates over 80%. Usually the agent had no problem to learn what moves are invalid and it usually had invalid moves below $5%$, but it had troubles learning a good policy for actually winning games against the classic agents. With the actor-critic agent it was easier to find parameters for which the algorithm converged, at least on $(4,4)$ boards.
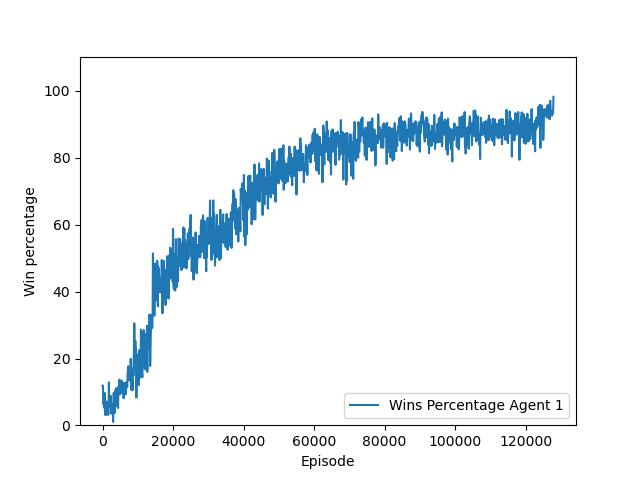
Figure 4: Example for the evolution of win rate as a function of the training episode during training of the actor-critic agent on a $(4,4)$ board.
For the rewards we settled in the end with
- Get number seeds placed into own house as rewards minus 0.1 (to make it less favorable to gain no points)
- For a win get +10
- For a loss get -10
- For an invalid move get -5 and the game is over
It also turned out that it was hard to train against the random agent. Training worked best against the MaxScore and MaxScoreRepeat agents and in the end we settled with the MaxScoreRepeat agent for training of the AC and REINFORCE agents.
Training on larger boards/boards with more seeds, i.e., $(6,4)$ and $(6,6)$, did not lead to a high enough win rate with, neither the AC, nor the REINFORCE agent, even after tuning the parameters or after trying with various random seeds. We may need improvements to the models, which we are going to discuss in the Outlook section and hopefully we will be able to produce well trained agents for the larger boards, too.
Comparison
For the comparison we let every agent play $N=1000$ games against every other agent, including itself, with the exception of the RL agents, as currently it can only play as player 1. Updating the environment, so that it is possible to play as player 2 is part of the planed improvements. Draws are not taken into account when calculating the win rate.
In Table 1 we compare the classic agents against the RL agents on a $(4,4)$ board. From the classic agents the random agent performed worst, but a slight advantage for player 1 can be seen there, which may be related to the advantage the player 1 has in Kalah. The MaxScore agent performed already reasonably well with just a few lines of code. It can easily beat random chance and if played against itself also a slight advantage for player 1 is visible. The MaxScoreRepeat agent improved the scores even further and is only beaten more often by the Minimax agent. The Minimax agent clearly is the best classic agent, winning most of the games against the other agents. The reinforcement agents did perform reasonably well themselves. Especially the AC agent was able to outperform the classic agents including the Minimax agent.
| vs | Random | MaxScore | MaxScoreRepeat | Minimax |
|---|---|---|---|---|
| Random | 50.54 | 21.37 | 15.13 | 17.63 |
| MaxScore | 82.84 | 53.02 | 23.68 | 19.58 |
| MaxScoreRepeat | 87.94 | 84.71 | 67.56 | 48.23 |
| Minimax | 86.57 | 82.87 | 74.68 | 59.15 |
| Reinforce | 84.01 | 87.50 | 77.64 | 39.77 |
| ActorCritic | 89.60 | 90.60 | 88.88 | 64.36 |
The comparison on the larger board with six bins each side and four seeds in each bin, i.e., $(6,4)$ in our notation, must be done without the RL agents, because, as we discussed in the previous section, we were not able to train a well-performing RL agent for larger boards. However, we are still comparing the classic agents for the larger boards. The biggest difference to the smaller board is that player 1 has a much higher win rate in case of the first three agent types. For minimax it is not so clear and the performance seems to be en-par with the performance on the smaller board, with the exception of the matchup against the MaxScoreRepeat agent, where the Minimax agent performed worse, but still winning more than half of the games.
| vs | Random | MaxScore | MaxScoreRepeat | Minimax |
|---|---|---|---|---|
| Random | 50.05 | 3.68 | 0.51 | 3.13 |
| MaxScore | 96.74 | 56.94 | 5.25 | 12.83 |
| MaxScoreRepeat | 99.30 | 97.78 | 74.05 | 73.57 |
| Minimax | 98.19 | 91.91 | 59.69 | 64.05 |
| Reinforce | N/A | N/A | N/A | N/A |
| ActorCritic | N/A | N/A | N/A | N/A |
On the $(6,6)$ the results, Table 3, look more similar to the $(4,4)$ board again, except for the random agent. The Minimax agent was still performing well against the other agents despite the depth of only $D_{max}=4$ which we used.
To see how a larger depth for the minimax algorithm changes things, we did another calculation on a $(6,6)$ board, but this time with $D_{max}=6$. This version of the Minimax agent is depicted as “Minimax 6” in Table 3. It drastically increased the calculation time, but did further improve the win percentage of the Minimax agent.
| vs | Random | MaxScore | MaxScoreRepeat | Minimax | Minimax 6 |
|---|---|---|---|---|---|
| Random | 49.95 | 2.83 | 1.30 | 0.70 | 1.80 |
| MaxScore | 97.39 | 53.06 | 14.81 | 14.51 | 14.42 |
| MaxScoreRepeat | 99.20 | 93.47 | 64.42 | 50.05 | 42.20 |
| Minimax | 97.90 | 91.47 | 76.51 | 65.13 | N/A |
| Minimax 6 | 99.40 | 94.24 | 82.47 | N/A | 67.43 |
| Reinforce | N/A | N/A | N/A | N/A | N/A |
| ActorCritic | N/A | N/A | N/A | N/A | N/A |
Summary
In this first part of what’s, hopefully, going to be a series of posts, we discussed how to play the board game Kalah with classic agents and how reinforcement learning can be used to successfully learn the game and win against classic agents, at least on small enough game boards. We also found that the training of a reinforcement model tends to be hard and a lot of hyperparameters tuning, i.e., fiddling with parameters, including the discount factor, rewards and learning rates, can be necessary. However, even though we implemented only two simple reinforcement algorithms, REINFORCE and actor-critic, it worked quite well. There is also lots of room for improvements, which may lead to even better performing RL agents.
Outlook
The next step will be implementing improved versions of REINFORCE. Especially we want to batch together episodes in the update step which should reduce the variance, i.e., should allow for a much more stable model over training time, and hopefully will lead to an improved performance and an easier trainable model. In addition, we will look into improvements to the actor-critic method. Especially we will see how advantage actor-critic (A2C) and asynchronous advantage actor-critic (A3C) models are implemented and how they perform in comparison to our current agents.
For the training process itself we are considering moving away from training always against one type of classic agent more to a heterogeneous approach were we train against various types of agents, which should hopefully improve the overall performance of the RL agents.
From the implementation point of view improvements to the environment and to the Kalah board will be made to allow the RL agent to play as the second player. We should also refactor the current code base so that it is easier to plot various metrics of the machine learning process and also to make it easier exporting these plots.
A distant goal will also be to make this implementation more user friendly so that a human player can easily play against the agents, or even better, a graphical/web interface….
References
[1] https://en.wikipedia.org/wiki/Reinforcement_learning
[2] https://en.wikipedia.org/wiki/Kalah
[3] https://pytorch.org/
[4] Mnih, Volodymyr; Kavukcuoglu, Koray; Silver, David; Graves, Alex; Antonoglou, Ioannis; Wierstra, Daan; Riedmiller, Martin (19 December 2013). “Playing Atari with Deep Reinforcement Learning”. arXiv:1312.5602.
[5] Adrià Puigdomènech Badia; Piot, Bilal; Kapturowski, Steven; Sprechmann, Pablo; Vitvitskyi, Alex; Guo, Daniel; Blundell, Charles (30 March 2020). “Agent57: Outperforming the Atari Human Benchmark”. arXiv:2003.13350.
[6] Silver, David; Huang, Aja; Maddison, Chris J.; Guez, Arthur; Sifre, Laurent; Driessche, George van den; Schrittwieser, Julian; Antonoglou, Ioannis; Panneershelvam, Veda; Lanctot, Marc; Dieleman, Sander; Grewe, Dominik; Nham, John; Kalchbrenner, Nal; Sutskever, Ilya; Lillicrap, Timothy; Leach, Madeleine; Kavukcuoglu, Koray; Graepel, Thore; Hassabis, Demis (28 January 2016). “Mastering the game of Go with deep neural networks and tree search”. Nature. 529 (7587): 484–489. https://doi.org/10.1038/nature16961.
[7] Berner, C., Brockman, G., Chan, B., Cheung, V., Debiak, P., Dennison, C., Farhi, D., Fischer, Q., Hashme, S., Hesse, C., Józefowicz, R., Gray, S., Olsson, C., Pachocki, J.W., Petrov, M., Pinto, H.P., Raiman, J., Salimans, T., Schlatter, J., Schneider, J., Sidor, S., Sutskever, I., Tang, J., Wolski, F., & Zhang, S. (2019). Dota 2 with Large Scale Deep Reinforcement Learning. ArXiv:1912.06680.
[8] Vinyals, O., Babuschkin, I., Czarnecki, W.M. et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 575, 350–354 (2019). https://doi.org/10.1038/s41586-019-1724-z
[9] https://en.wikipedia.org/wiki/Minimax
[10] https://en.wikipedia.org/wiki/Alpha%E2%80%93beta_pruning
[11] Williams, Ronald J. “Simple statistical gradient-following algorithms for connectionist reinforcement learning.” Reinforcement Learning. Springer, Boston, MA, 1992. 5-32.
[12] Lapan, Maxim. “Deep Reinforcement Learning Hands-On”, Second Edition, Packt, Birmingham, UK, 2020, 286-308.
[13] A. Barto, R. Sutton, and C. Anderson, Neuron-like elements that can solve difficult learning control problems, IEEE Transactions on Systems, Man and Cybernetics, 13 (1983), pp. 835–846.